
Matt Wolfe
AI Audio Summaries
20 videos summarized
1 follower on BriefTube
Last summary: Jun 5, 2026
AI Audio Summaries
20 videos summarized
1 follower on BriefTube
Last summary: Jun 5, 2026
Read AI summary
YouTube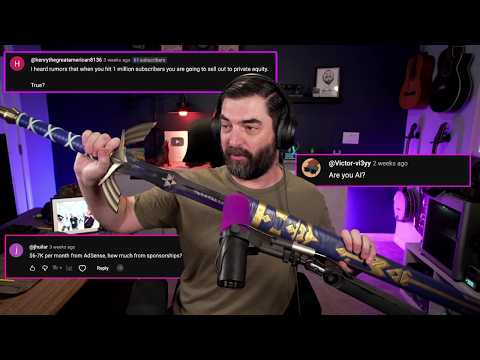
The creator addresses a variety of viewer questions, starting with the popular inquiry about his intro videos. He explains that for a recent wolf morphing intro, he used ChatGPT to generate an image of a wolf in his office chair, ensuring the correct aspect ratio. He then used Runway ML, attempting the morphing effect thirteen times before achieving a satisfactory result. The prompt specified a smooth transition from wolf to man, with the wolf's features gradually becoming human-like, ending with the man staring silently. He emphasizes the need for specificity in AI prompts, like instructing it not to add extra speech. Regarding who creates his intros, he clarifies that he and his kids come up with the ideas, with viewer suggestions sometimes incorporated, like the wolf intro. He also addresses questions about his team. While he edits most of his videos himself in real-time, using a Stream Deck and then refining in Da Vinci Resolve, he has a small team of contractors. This includes two editors for short-form content and ads, a person named John for titles and thumbnails, and a production assistant named Roya who manages social media and editors. Vishall helps with the Future Tools website, and Katherine writes the newsletter. He also works with Smooth Media for sponsorships and an agency for ad management. His monthly overhead for these services and subscriptions is estimated at around $23,000-$25,000.
Read AI summary
YouTube
This week brought a flurry of AI news, particularly from OpenAI. A major highlight is the introduction of GPT 5.5 Instant, OpenAI's new default model in ChatGPT, replacing GPT 5.3 Instant. While not a revolutionary leap, it offers incremental improvements, promising smarter, more accurate, and concise answers tailored to the user. For instance, in a math problem, the new model provided a direct solution, unlike its predecessor which initially struggled and then found no real solution. It also delivers more concise responses to queries, as demonstrated by shorter scroll bars in comparisons. Additionally, it offers more personalized answers by leveraging memory of past interactions. This model is now available to all ChatGPT users, including those on free and paid plans, and is also integrated into Microsoft 365 Copilot. OpenAI also showcased impressive new real-time voice models, currently available only through the API. These include GPT Realtime 2 for complex reasoning, GPT Realtime Translate which translates speech from over 70 input languages into 13 output languages in real-time, and GPT Realtime Whisper for live speech-to-text transcription. Demos highlight the translation model's ability to translate while the speaker is talking, even handling interruptions and technical terms. The Realtime 2 demo illustrated a conversational AI that can manage calendar requests and update CRM systems, with the notable feature of being able to be paused and resumed on command. This capability to tell the AI to "stay quiet" while engaging in other conversations is a significant advancement for natural interaction. While not yet in ChatGPT or Codex, a limited demo of GPT Realtime 2 is accessible via the OpenAI playground, though it incurs API costs.
Read AI summary
YouTube
The speaker has developed a "second brain" knowledge management system that integrates a wiki, a CRM, and a journaling function, all accessible through chat. This system aims to go beyond simple data storage by making information actively usable. The system is built upon three core pillars:
Read AI summary
YouTube
This week saw significant developments in the AI world, particularly with the release of DeepSeek V4. This new open-source model is nearly state-of-the-art, boasts a 1 million token context length, and offers highly competitive pricing. Compared to models like GPT 5.5, GPT 5.4, Claude Opus 4.7, and Gemini 3.1, DeepSeek V4 is drastically cheaper, costing $1.74 per million input tokens and $3.48 per million output tokens, while offering comparable performance to previous generations of leading models. This pricing structure and its open-source nature are causing concern among major AI companies, as it allows enterprises to achieve similar capabilities at a much lower cost and potentially run models locally for enhanced security and privacy. The emergence of such efficient and cost-effective models from regions like China, despite export restrictions on powerful GPUs, highlights innovative training methods that challenge the dominance of US-based frontier labs. Nvidia also released Neotron 3 Nano Omni, an open, multimodal model supporting vision, audio, and language. Designed for AI agents, it can process text, images, audio, video, and documents, and can be run locally, reducing operational costs to just electricity. The growing capabilities of open-weight models, once thought to be far behind state-of-the-art, are now making them suitable for most common use cases, such as document summarization or customer support, often making more expensive models overkill.
Read AI summary
YouTube
OpenAI has released ChatgPT images 2.0, a powerful image model that offers numerous practical applications beyond simple image generation. This model can create slide decks, Instagram carousels, and visually explain complex information with high accuracy. The presenter tested countless prompts to demonstrate its capabilities, from YouTube content creation to business applications and personal organization. For YouTubers, ChatgPT images 2.0 can generate diverse thumbnail concepts. Given a prompt to create a YouTube thumbnail concept board for a video about Chat GPT Images 2.0, the model produced six distinct concepts in a 2x3 grid, each with different visual metaphors, facial expressions, layouts, and short texts. While initially generated as squares, the model could adjust them closer to the 16:9 aspect ratio, providing a good starting point for design. It also proved capable of creating A/B test sheets for thumbnails, offering three different concepts with unique hooks to test audience engagement. Furthermore, it can storyboard video intros, generating a nine-frame sequence with detailed visuals for each shot, such as a skeptical creator, old AI images with garbled text, new AI images with readable text, and various use cases like menu design, infographics, and YouTube thumbnails.
Read AI summary
YouTube
This week has been incredibly busy in the world of AI, with numerous significant updates from OpenAI, Anthropic, and other major players. OpenAI launched GPT 5.5, a new model available in ChatGPT and Codex, which is designed to understand user intent faster and handle more work with less input. This means users can provide fewer details and less context in prompts, yet achieve better results. GPT 5.5 excels in code writing and debugging, online research, data analysis, document and spreadsheet creation, and software integration. It is also more token-efficient than its predecessor, GPT 5.4, using fewer tokens for the same tasks, which is important given its higher pricing of $5 per million input tokens and $30 per million output tokens (double the cost of GPT 5.4).
Read AI summary
YouTube
This week in AI saw significant updates from major players like OpenAI, Google, and Anthropic, with a recurring theme of new user interface rollouts and enhanced AI agent capabilities. OpenAI's Codec app received notable upgrades, positioning it as a potential "super app" for OpenAI's services. Codec can now operate a computer alongside the user, generate images using GPT Image 1.5, remember preferences, and handle ongoing tasks. It features background computer operation, allowing it to see, click, and type with its own cursor without interfering with the user's work. Multiple agents can run in parallel on a Mac. The app now includes an in-app browser, enabling users to comment on web pages to provide context for Codec's actions, such as resizing elements or adding logos. Demonstrations showed Codec generating a website mockup from a text prompt and then building the site, followed by using a comment to instruct it to replace a section's background with a generated image that didn't interfere with text. Codec also successfully created a local macOS desktop version of Connect 4, which it could then play against itself to test the user experience. The speaker expressed growing appreciation for Codec's evolving capabilities and user-friendliness.
Read AI summary
YouTube
This video addresses various questions from viewers, covering topics like YouTube earnings, video editing, AI's impact on creators, and tech recommendations. The creator demonstrates how he makes his video intros, which often feature a "claw" picking him up. He records himself off-camera, then walks into the frame, or, for the claw effect, sits in a corner before moving to his chair. He uses DaVinci Resolve to cut the video and export still frames of himself off-camera and seated. These stills are then uploaded to Leonardo, a video generation tool where he is an advisor and has equity. Leonardo is preferred for its variety of video models like Cling, VO, and Halo 2.3. He uses the two still frames and a text prompt to generate the intro, often trying multiple models (e.g., VO3.1, Cling 3.0) until satisfied. Both Cling Video 3.0 and VO 3.1 also generate audio, which he typically uses. If Leonardo doesn't produce the desired result, he moves to Runway ML, which offers Seed Dance 2.0, another decent video model. The final chosen intro is then added to the beginning of his video.
Read AI summary
YouTube
This week's AI news roundup covers Anthropic's Claude Mythos and Project Glasswing, Meta's MuseSpark, ZAI's GLM 5.1, Google Gemini updates, and the AI video model C-Dance, among other developments. The most significant news is Anthropic's Claude Mythos, a frontier AI model described as a general-purpose, unreleased model with advanced coding capabilities. According to Anthropic, Mythos can surpass most humans in finding and exploiting software vulnerabilities. It has already identified thousands of high-severity vulnerabilities, including some in major operating systems and web browsers. Benchmarks show Mythos significantly outperforming previous models like Opus 4.6 in cybersecurity vulnerability reproduction, software engineering, and multimodal understanding. For instance, it found a 27-year-old vulnerability in OpenBSD and a 16-year-old vulnerability in FFMPEG.
Read AI summary
YouTube
This week brought significant developments in the AI landscape, starting with the unexpected leak of Anthropic's Claude code. The leaked source code revealed a sophisticated three-layer memory architecture that moves beyond traditional "store everything" retrieval. This system, at its core, uses "memory MD," a lightweight index of pointers that is perpetually loaded into context. This index stores locations rather than raw data, and transcripts are "grepped" for specific identifiers, meaning the system searches text for patterns to retrieve relevant information. Even more intriguing was the discovery of "Chyros" within the leaked code, described as an "autonomous demon mode." This feature would allow Claude to operate as an always-on background agent, performing memory consolidation while the user is idle. Chyros is designed to be a proactive AI that acts without explicit prompts. It runs 24/7, checking every few seconds if there's anything worth doing. If it acts, it can fix code errors, respond to messages, update files, and run tasks—essentially anything Claude can already do, but autonomously. It also possesses exclusive tools: push notifications to reach users outside the terminal, file delivery for sending created content without being asked, and pull request subscriptions to monitor GitHub for code changes. Examples of its potential include automatically restarting a website that goes down, replying to customer complaint emails at 2 AM, or fixing typos on a website, all while the user is away. This hints at a "post-prompting era" where AI becomes a proactive background agent, learning user needs and acting on their behalf. Similar proactive AI developments are also seen with OpenClaw's cron jobs and autonomous heartbeats. The leak also showed more evidence of "Capiara" (or "Mythos"), Anthropic's next-level model, and a "hidden buddy system" resembling a Tamagotchi-style terminal pet, which some speculate was a planned April Fool's joke that was sidelined due to the leak. Anthropic's head of Claude, Boris Churnney, attributed the leak to a developer error, emphasizing a focus on process improvement rather than individual blame. While no private customer information was leaked, the incident may lead to spin-offs of Claude code leveraging the open-source material.
Read AI summary
YouTube
This week has seen a significant surge of news and updates in the AI world, with companies like Anthropic and Google leading the charge with new features and model releases. Anthropic, in particular, has been consistently shipping new functionalities, with reports indicating 74 releases in just 52 days. Recent additions include cloud tasks, projects, co-work domain selection, effort and skills tracking, various cloud code updates, computer use capabilities, scheduled cloud code execution, cloud code channels for teams and enterprise, and the ability to interact with tools like Figma, Amplitude dashboards, and canvas slides from a mobile phone using Claude. A particularly impactful feature for Anthropic is the "computer use" capability for Claude. Launched on the 23rd, this allows Claude to control a user's computer, including mouse and keyboard actions. When combined with the "dispatch" feature, which enables control of Claude Code and Claude Co-work from a phone, users can remotely instruct their computers to perform tasks. While this feature requires a paid plan and needs to be enabled in settings, it offers the potential for hands-free computer operation. However, the current implementation is noted to be quite slow, with initial attempts at tasks like opening applications taking considerable time. The speaker demonstrated opening Da Vinci Resolve, which took approximately five minutes, highlighting that while functional, it's not yet efficient for tasks that can be done quickly manually. The primary benefit of this slow but capable feature appears to be for remote task execution where time is less critical than task completion.
Read AI summary
YouTube
Bernie Sanders and Alexandria Ocasio-Cortez have introduced the "Artificial Intelligence Data Center Moratorium Act," proposing a nationwide pause on new data center construction until federal AI legislation is enacted. This legislation would need to establish protections for workers and consumers, safeguard the environment, and defend civil rights. The proposed bill has sparked polarized reactions, with one side arguing it would hinder American progress and benefit China, while the other supports a complete halt to data center construction due to energy consumption and AI's perceived dangers. The proponents of the moratorium highlight several key concerns. Foremost among these is the impact on residential energy costs. Data centers are significant consumers of electricity, and their construction is linked to rising energy prices for households. Reports indicate that in states with a high concentration of data centers, such as Illinois, Virginia, Ohio, Texas, and California, residents have experienced substantial increases in their electricity bills. The Department of Energy data suggests an average increase in electricity prices, with independent market monitors attributing a significant portion of this rise in capacity prices to data centers. A single data center campus can consume power equivalent to the population of San Francisco, and electricity demand from data centers is projected to grow by 15-20% annually. This creates a supply and demand imbalance; as data centers draw heavily on local electricity grids, they reduce the available supply, driving up prices for residential users who share the same grid.
Read AI summary
YouTube
The Nvidia GTC conference in San Jose, California, often described as the "Super Bowl" or "Burning Man" of artificial intelligence, serves as a massive showcase for the company’s latest innovations. While much of the event is tailored toward enterprise-level data centers, several key announcements from the Day 1 keynote and surrounding events are particularly relevant to the general public and AI enthusiasts. A primary focus of the conference was OpenClaw, an open-source project that has gained significant traction in the AI community over the last few months. OpenClaw is designed to transform standard AI models into autonomous agents equipped with memory and the ability to use various tools, essentially allowing them to act as human workers. To support this ecosystem, Nvidia announced "Nemo Claw," a tool that simplifies the installation of OpenClaw to a single line of code.
Read AI summary
YouTube
This week brought a significant wave of updates in the AI landscape, focusing on interactivity, autonomous agents, and advanced image manipulation. The primary highlights involve new features from Anthropic and OpenAI, the expansion of Perplexity’s autonomous "Computer," and innovative layering tools in Canva. ### Interactive Visualizations: Claude vs. ChatGPT
Read AI summary
YouTube
The promise of Artificial Intelligence has long been centered on the idea of radical productivity and the reduction of human workload. However, a growing body of research and anecdotal evidence suggests a counter-intuitive reality: AI is not making work easier; it is intensifying it, leading to a phenomenon now described as "AI brain fry." This summary explores the cognitive costs of offloading mental labor to machines, the paradox of increased speed, and the scientific evidence suggesting that our reliance on these tools may be causing our critical thinking skills to atrophy. **The Intensification of Work and Workload Creep**
Read AI summary
YouTube
This week in the world of artificial intelligence was marked by a flurry of significant model releases from OpenAI and Google, alongside an escalating political and corporate drama involving Anthropic, OpenAI, and the United States government. The following summary breaks down the key technological updates and the unfolding conflict within the industry. ### OpenAI’s Rapid-Fire Releases: GPT 5.3 and 5.4
Read AI summary
YouTube
In this video, the speaker explores a significant advancement in mobile technology: the ability to run high-quality AI models locally on a smartphone without an internet connection. This capability is particularly useful for users who prioritize privacy, as it ensures data is not sent to cloud services like OpenAI, Google, or Anthropic. It also provides utility in offline environments, such as during a flight. The core of this demonstration centers on an app called "Locally AI," developed by Adrian Gronden. The app allows users to download and run various open-weight models directly on their iPhones. While several models are available, including Apple’s Foundation model, Gemma 2, and Llama 3.2, the speaker focuses on the newly released Qwen 3.5 family. Released on March 2nd, the Qwen 3.5 models come in four sizes: 800 million, 2 billion, 4 billion, and 9 billion parameters. According to the transcript, these models are highly capable, with benchmarks suggesting they perform on par with some of the best open-source models and even outperform "GPT5 Nano" in certain tests.
Read AI summary
YouTube
Google has officially launched Nano Banana 2, a new state-of-the-art image generation model also known as Gemini 3.1 Flash. The central value proposition of this model is providing "Pro-level" intelligence and image quality at "Flash-level" speeds. This summary breaks down the key features, performance tests, and practical applications of the model based on hands-on evaluations. ### Overview and Accessibility
Read AI summary
YouTube
Anthropic recently published a provocative blog post accusing three prominent Chinese AI companies—Deepseek, Moonshot, and Miniax—of conducting a massive, coordinated campaign to "steal" their AI capabilities. This operation involved approximately 24,000 fake accounts and 16 million exchanges. Anthropic has labeled this an "industrial-scale distillation attack" and framed it as a significant national security concern. To understand the gravity of these claims, one must first understand what model distillation is, how these specific companies allegedly carried it out, and the broader legal and ethical controversies surrounding the AI industry. Model distillation is a technique used to create smaller, faster AI models by using a larger, more powerful model as a "teacher." In a standard training process, a company like Anthropic might spend hundreds of millions of dollars and several months training a massive model like Claude Opus. This requires scraping the entire internet, utilizing vast libraries of books, and employing massive GPU clusters. Distillation offers a shortcut. Instead of starting from scratch, a "student" model sends prompts to the "teacher" model and records the responses. Modern "thinking" models often provide a "chain of thought," showing the logic used to reach a conclusion. By capturing millions of these prompt-response pairs, the student model learns to mimic the teacher's reasoning and behavior at a fraction of the cost and time. While companies like Anthropic and OpenAI use distillation internally to create smaller versions of their own models—such as Claude Haiku or GPT-4o mini—the controversy arises when one company performs this process on a competitor’s model without permission.
Read AI summary
YouTubeBriefTube monitors your YouTube channels, generates AI-powered audio summaries, and delivers them wherever you listen. Telegram, Discord, Slack, or your podcast app. Fully automated.
Start free trial